逆向嵌入式设备引导程序(U-Boot)- 第一部分
译文声明
本文是翻译文章,文章原作者:ZI0BLACK & THEZERO
原文地址:https://www.shielder.com/blog/2022/03/reversing-embedded-device-bootloader-u-boot-p.1/
译文仅供参考,具体内容表达以及含义原文为准。
Reversing embedded device bootloader (U-Boot) - p.1 逆向嵌入式设备引导程序(U-Boot)- 第一部分
本博文并不是ARM固件逆向工程入门教程或攻击特定物联网设备的指南。 我们的目标是分享我们的经验,也许可以为您节省一些宝贵的时间和减少一些让您头痛的困难。
Bootrom
在这两篇文章的系列中,我们将分享对低级别(low-level)二进制逆向的一些方面的分析。为什么? 嗯,我们必须承认,我们在收集信息以建立关于这个主题的基本知识方面遇到了一些困难,而且我们发现的材料往往不够全面,或者很多方面被认为是理所当然的。出于这个原因,我们在这里分享我们从多个来源中学到的东西,并试图在这两篇文章中整合它们,同时也试图提供一些操作背景,并分析更复杂或晦涩的方面。
一些背景
- CPU是ARM-Cortex A7.
- bootloader是自定义的U-Boot(二进制被strip过)
- 我们找到了SOC的datasheet
- 我们在厂商网站找到了固件镜像
- 内核和根文件系统被加密了,很可能是基于自定义的加密方法
- IoT设备没有使用ARM Trust Zone.
- 设备强制使能了安全启动
主要目标是逆向自定义加密函数、检索加密密钥并解密内核。这次尝试以一种略微不同的方式结束,但是,剧透警告,我们确实解密了内核文件。
什么是bootloader?
计算机启动时运行的第一个程序是引导加载(bootloader)程序,由bootloader加载操作系统。它通常存储在计算机硬件的EEPROM或NOR闪存(一种持久闪存)上。它的功能是初始化各种系统组件:从CPU寄存器到设备控制器和中央内存内容(central memory content)。启动程序需要定位、加载到内存中,然后将控制转移到操作系统,这样它就可以开始向系统提供服务了。
一些计算机系统使用多级引导过程:当计算机第一次打开时,一个位于非易失性内存中的小bootloader,称为BIOS,被执行;这个初始程序接下来加载位于磁盘固定区域(称为引导块)的第二个bootloader。第二个启动程序比第一个bootloader更复杂(想想Grub之类的程序,它有成千上万行代码),它完成了繁重设置工作以便更容易地加载操作系统。
对于一个真实的例子,我们建议查看这个外部资源: ARM引导进程。
我们不会详细讨论Das U-Boot实现的技术细节,但是可以肯定的是,U-Boot是一个主要用于嵌入式设备的开源主bootloader。
注意:主bootloader并不意味着U-Boot必须是第一阶段的bootloader, 它可以在任何阶段使用。
四处看看
下载固件后,我们使用Binwalk来提取它。

不幸的是,这并没有产生预期的结果,因为它没有识别或提取(预期的)各种分区。
这通常意味着文件可能以某种方式加密,或者有一种自定义格式(虽然不太可能,但有这种可能性)。我们可以通过检查单个文件的熵来验证第一个假设。二进制文件往往有某些指令的频繁重复(例如,前言(prologues),nop序列等),数据结构几乎不是随机的。在数据段中,当不是所有内容都可以延迟到bss时,长序列的零也很常见。相反,一个加密的文件将有几乎完美的熵,因为这是一种健壮的加密方案的目标。译者注:熵越大代表越混乱,如果一个固件的熵值稳定在1附近,则可以猜测大概率是被加密过
要做这个熵值检查,可以使用Binwalk –entropy标志,来检查所有固件文件的熵。正如您可以从下图注意到的那样,大多数文件的y轴熵值都是1 —— 这证实了它们是被加密过的。
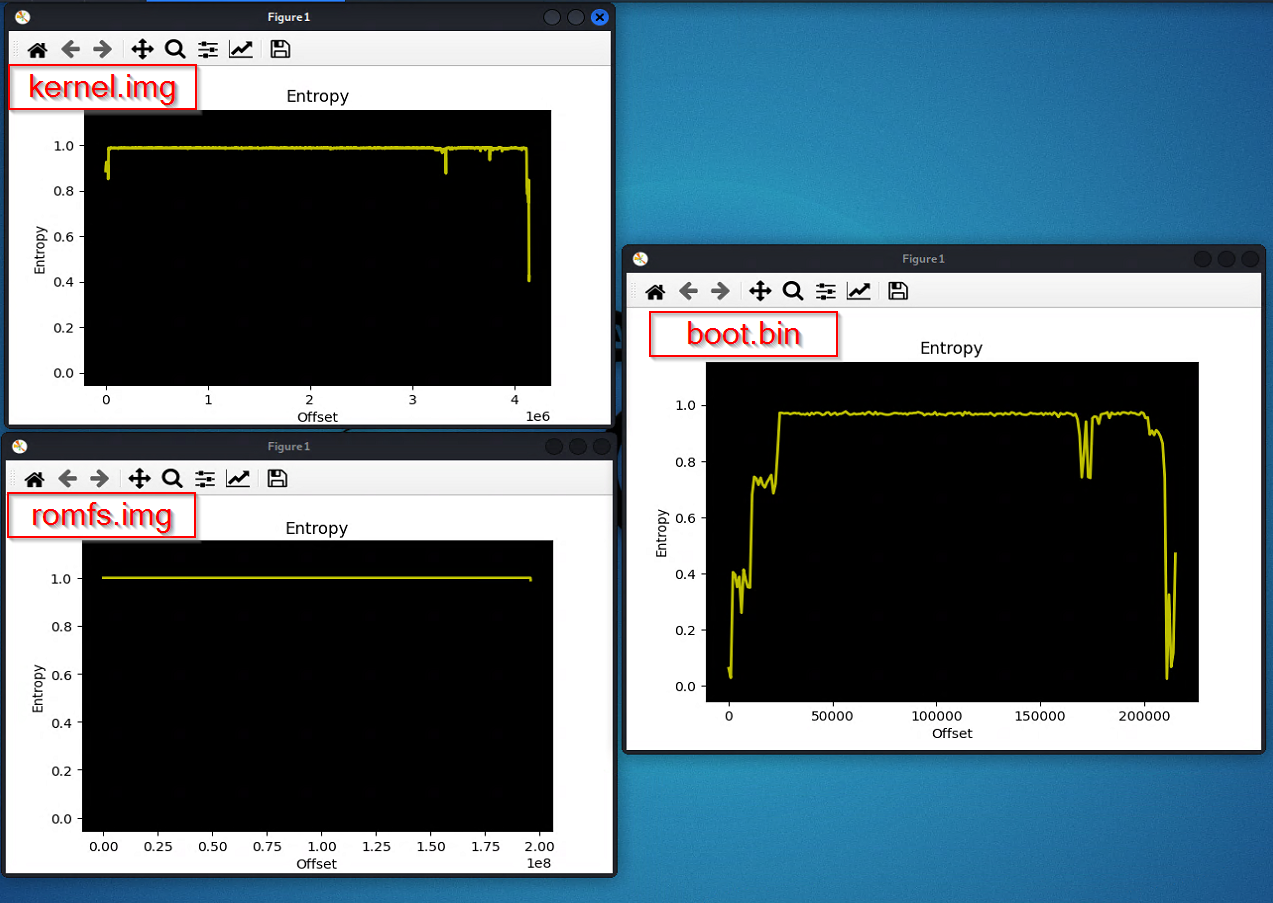
从上图可以看到,boot.bin文件的熵并没有稳定在1附件。看到上下波动的图形了吗?根据前面提到的知识。我们可以大胆的猜想,bootloader是明文的,没有加密。而由bootloader在启动内核执行之前在引导过程中解密其他分区。我们仍然不知道bootloader中的大部分解密逻辑:它可能可以是解密的所有镜像或只只能解密内核,然后由内核自己维护的密钥/算法来解密其余的文件系统。后一种方法在加密和验证链中并不少见。
基于当前的假设,我们使用Binwalk(没有黑魔法,是简单的使用Binwalk -e firmware.bin)从固件中提取引导镜像,然后再次运行Binwalk尝试提取boot.bin文件。让我们运行strings boot.bin以确保我们不是疯了。
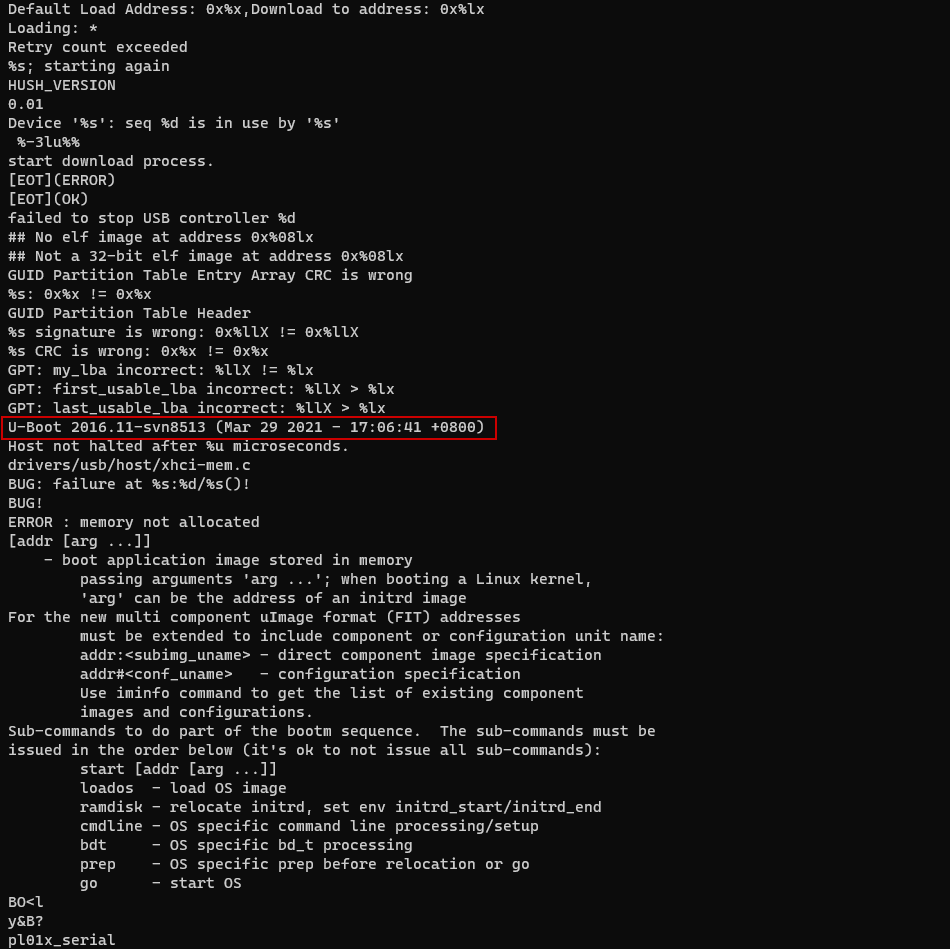
耶 - 我们有一个没加密的U-Boot二进制文件! 让我们检查启动参数 strings boot.bin | grep args.
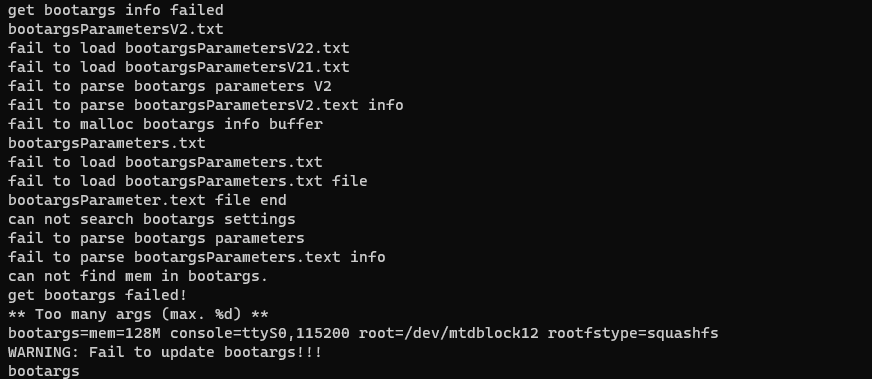
没有特别的,但现在我们知道Squashfs Rootfs存储的位置:/dev/mtdblock12。
我们还能了解到什么? 让我们寻找一些地址来了解这个东西在内存中的样子。查看datasheet,我们发现一个表映射了所有的设备地址,如果你熟悉ARM,那么当看到RAM从0x8000_0000开始这种情况,你并不会感到奇怪。
| 试试通过grep获取更多地址信息: strings u-boot.bin | grep 0x |
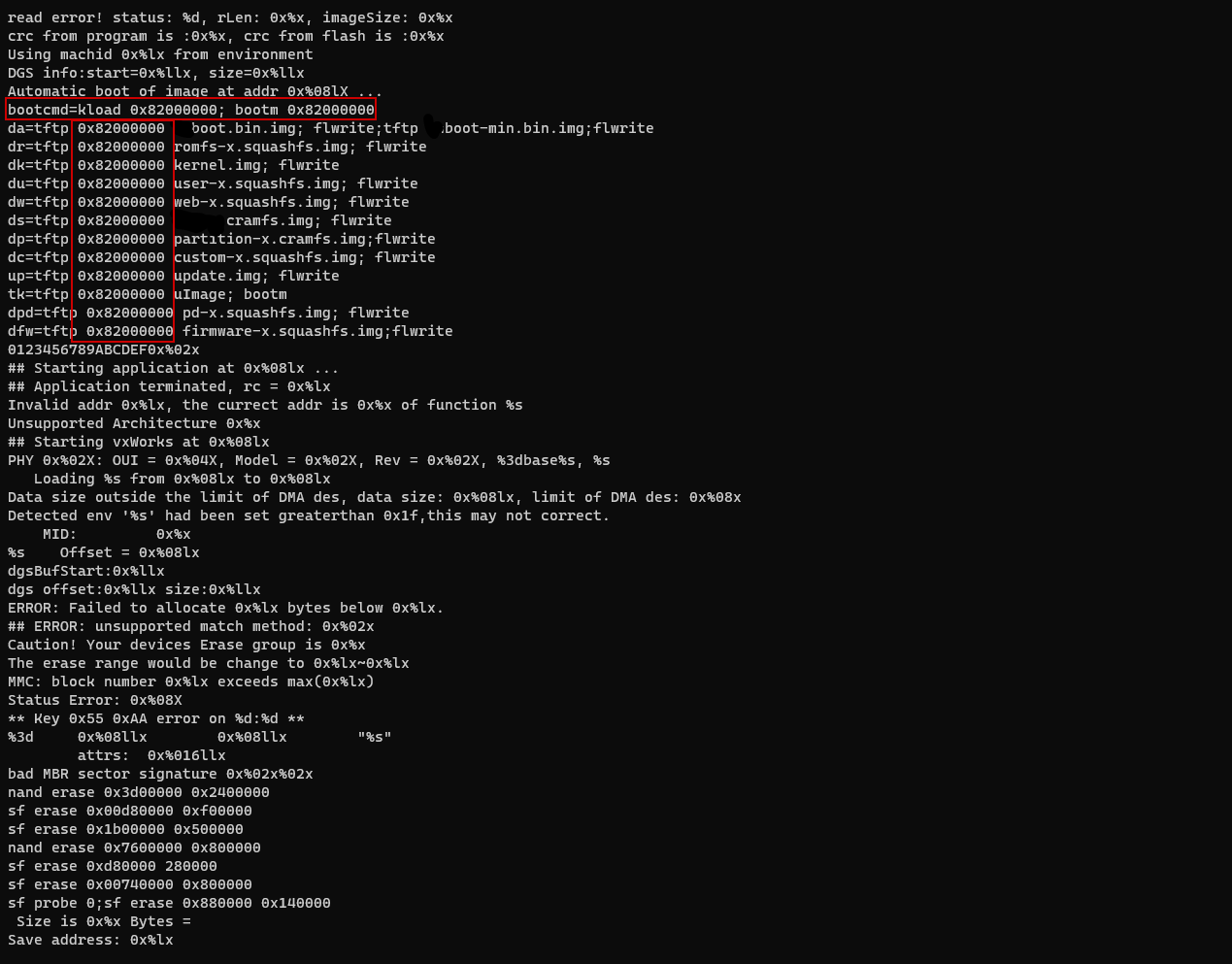
好的,如果RAM从0x8000_0000开始,那么内核被加载到0x8200_0000。但是从0x8000_0000到0x8200_0000这个空间加载了什么呢? U-Boot被加载到哪? 它应该被加载在一个固定的地址,毕竟它是bootloader啊。
作者zi0black:我刚在大学参加过操作系统考试,对此我很有信心。我本可以更深入地研究datasheet或其他文档来找到答案,但我选择了另一种方式。
裸机二进制分析(Dissection of a bare metal binary)(ARM)
二进制文件是计算机加载和解释/执行的本质。而二进制文件本质上只是一系列字节,存储在内存中,并且拥有足够的信息来保持运行。在实际情况下,为了能支持动态链接,共享库,运行时重新定位以及我们几乎可以授予的所有其他灵活性比如我们在一个系统上编译二进制文件并在另一个系统上运行它时,或者看到它选择安全更新后固定库,为了支持提到的这些功能,我们需要给二进制集成更多信息。最重要的是,程序需要做一些有用的东西来满足其存在的意义(是的,让我们谈谈哲学)。为实现这一目标,很可能需要与系统交互,分配一些内存,也许将一些数据存储到磁盘。我们不指望所有二进制文件实现此逻辑:操作系统就是干这个用的。
上面描述的画面是您在Linux环境中运行程序(ELF)的一个普通遭遇。当然,建立这样的生态系统有一个不小的代价:您需要一个完全工作的操作系统、一个动态链接器和所有的库。在物联网或其他内存受限的环境中——或者在您不希望所有这些抽象层以某种方式存在的情况下(想想一些专门的云工作负载或类似的情况),可以让一个二进制文件做它需要的一切,并且只做它需要的事情。这是裸机计算(BMC)背后的核心思想。在BMC范式中,应用程序在没有任何操作系统(OS)或集中式内核支持的情况下运行,也就是说,在运行应用程序之前,没有中间软件被加载到裸机器上。
我们从BMC得到的只是一个大型的静态平面文件(flat file),它将开始执行和管理内存,处理中断和(如果需要)直接访问硬件。这在裸机二进制中很常见,因为他们是唯一在运行的实体,没有实施任何形式的虚拟内存,因为没有需要创建隔离的内存空间的需求,也不需要实现内存的分页。对于我们的分析来说,这意味着如果我们正在处理一个裸机二进制文件,我们将发现大量关于内存布局的信息,而我们通常能(例如ELF文件)发现运行时解析的重定位。不用说,U-Boot是一个裸机二进制程序。
中断
在开始我们的目标二进制代码并理解它的结构之前,让我们先简单地讨论一下中断。
硬件部件可以在任何时候通过向CPU发送信号来产生中断,通常是通过系统总线(一个处理系统中可以有很多总线,但系统总线是核心部件之间的主要通信路径)。中断还用于许多其他目的,对于操作系统和底层硬件之间的交互至关重要。当CPU接收到一个中断信号时,它停止当前的处理并立即跳转到某个固定的内存区域。
应该注意的是,在切换上下文上,没有黑魔法,上下文的切换由中断处理程序执行,除非CPU存在特殊的性质(例如,一组额外的寄存器,用于给程序员节省一些繁重的上下文切换工作)。中断处理程序负责保存当前状态/寄存器(上下文),并稍后还原它们以在完成服务后正确恢复中断指令流的执行。
内存区域基本上是一个固定大小的表项,包含专用中断服务例程的第一个指令的地址或直接第一个指令的地址。根据每个条目的大小和格式,一些指令可以直接存储在那里。这些可能不足以完全处理中断:通常情况下,它们是不够的,首先要做的就是转移到其他地方开始处理中断。对于存储的地址,CPU直接将其加载到程序计数器中。
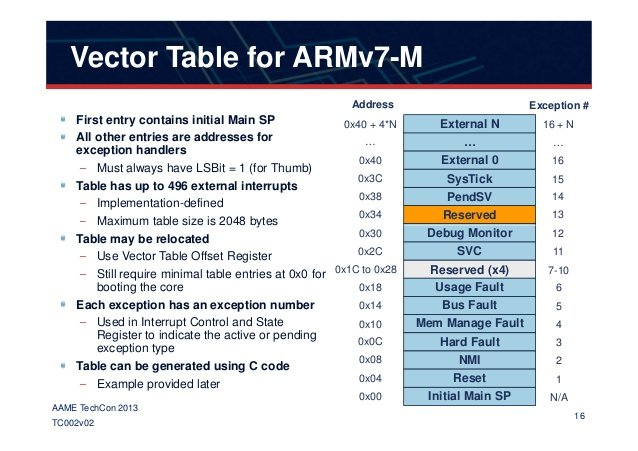
中断向量表
这个指针表,也被称为中断向量表(IVT),通常存储在中央内存的最低部分(例如,前n个位置,我们稍后会看到)。表项有一个索引,与中断中包含的索引相同,允许快速查找。
中断与系统异常非常相似,主要区别在于产生它们的组件:第一个由特定于体系结构的外设模块产生,而第二个由CPU产生。它们也是不可预测的,因此异常是确定的,并响应特定的程序行为。
当涉及到操作系统时,由内核来处理中断,但在裸机二进制文件中,如U-Boot,单个二进制文件应该包含并处理IVT。因此,在分析裸机二进制文件时,IVT是一个很好的起点。在我们的具体例子中,一个ARM设备,我们知道IVT应该被放置(它可以被重新定位)在地址空间的开头:0x00, 0x04, 0x08,这意味着找到IVT将带我们到二进制文件的开头。
下面是中断向量表的图形表示
在GitHub上搜索一段时间后,我们发现一些代码确认了我们正在分析的特定SoC/板的中断向量表的结构。由于它遵循了一些ARM SoC特定特征,所以它与前面一个略有不同。
.globl _start
_start: b reset
ldr pc, _undefined_instruction
ldr pc, _software_interrupt
ldr pc, _prefetch_abort
ldr pc, _data_abort
ldr pc, _not_used
ldr pc, _irq
ldr pc, _fiq
_undefined_instruction: .word undefined_instruction
_software_interrupt: .word software_interrupt
_prefetch_abort: .word prefetch_abort
_data_abort: .word data_abort
_not_used: .word not_used
_irq: .word irq
_fiq: .word fiq
_pad: .word 0x12345678 /* now 16*4=64 */
当处理器复位时,硬件将pc设置为0x0000,并通过获取0x0000的指令开始执行。当一个未定义的指令被执行或试图被执行时,硬件会将pc设置为0x0004,并在0x0004开始执行该指令。Irq中断,硬件完成它正在执行的指令,开始执行地址为0x0018的指令。 – old_timer on stackoverflow
如果想深入了解IVT、中断和异常处理,以及ARM CPU是如何启动的,请参阅参考资料部分。
召唤三头龙 Ghidra 配置
是时候开始在Ghidra中逆向我们的U-Boot二进制文件了。当我们在Ghidra中导入U-Boot时,会将它作为一个原始的二进制文件加载,我们应该告诉它关于CPU架构的信息。幸运的是,我们从datasheet中得知SoC由两个ARM-A cpu组成。使用Google对ARM-A17快速搜索显示,它是基于ARMv7-EL的。
我们可以根据发现的信息相应地配置加载器。
人工分析 Ghidra足够聪明,甚至在深入分析之前就能识别IVT。
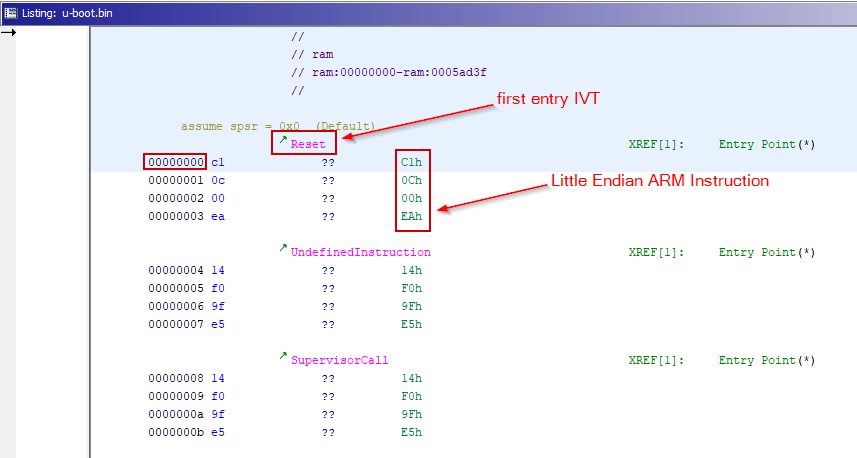
高亮显示的dword大小的十六进制序列是一条无条件的ARM指令。
从统计学上讲,无条件指令是最常见的,可以通过第一个位识别是否在0xE0-0xEF范围内判断是否为无条件指令(请记住,体系结构是小端序的,因此最重要的位是最后一个)。
关于指令大小的一点小跑题
Arm架构支持三种指令集:A64, A32和T32。A64和A32指令集有固定的32位指令长度。T32指令集是作为16位指令的补充集引入的,它支持改进用户代码的代码密度。随着时间的推移,T32演变成16位和32位混合长度的指令集。因此,编译器可以在一个指令集中平衡性能和代码大小。来自ARM开发者。
两个等价指令之间的区别在于它们在执行之前是如何被获取和解释的,而不是它们的功能。由于从16位到32位指令的扩展是通过芯片内的专用硬件完成的,所以它不会减慢执行速度。然而,较窄的16位指令在占用空间方面提供了内存优势。现在让我们假设在我们的例子中,CPU正在使用ARM的ARM(而不是ARM Thumb)指令集,所以我们正在使用32位的指令。记住,CPU可以在运行时切换到Thumb 模式。
让我们把指令转换成它的二进制表示形式
ea -> 11101010
00 -> 00000000
0c -> 00001100
c1 -> 11000001
ARM分支指令的结构如下
- 第31-28比特:条件
- 第27-25比特:固定序列
- 第24 比特:链接比特(link bit)
- 第23-0 比特:用补码表示的偏移

这条ARM指令是一个分支指令(用ASM代码中的B表示),其功能是跳转(如果满足条件)到地址(PC + 偏移),改变执行流程。
前4比特是1110,其对应于“忽略所有CPU标志”:aka无条件分支。
接下来的3位在分支指令中固定为101。
第7位指示分支是否应该存储链接以在执行后返回。如果设置为1,则在R14寄存器中存储地址,并且当函数执行完成时,CPU跳回该地址。在我们的情况下,该位设置为0,因此它将只是分支,而不将任何信息存储到R14寄存器。
最后一个部分存储了24比特的补码偏移量。将偏移量有符号扩展为32位,接下来左移2位以进行内存对齐,最后和PC + 8的值相加,得到的结果就是要跳转到的内存地址的位置。 译者注:偏移 =(目的地址 -(PC + 8)) / 4。所以offset左移两位,再加上pc+8即可获得要跳转的目的地址
使用Ghidra的反编译器,我们可以反编译第一个DWORD,并观察到每条指令都对应一个中断。除了第一个中断(“reset”),所有其他的都通过LDR汇编指令在PC内部进行偏移,这对我们来说特别有趣,因为我们知道RAM从哪里开始(0x8000_0000),但不知道二进制的偏移量。
Ghidra默认加载地址为0x0的原始二进制文件,但我们可以注意到,引用被突出显示为红色,因为它们指向二进制内存区域之外。我们从实际加载U-Boot的引用中推断,偏移量恰好是0x0080_0000。
作者zi0black:我必须感谢@blessthe28,他给了我一些关于裸机二进制内IVT结构的说明。
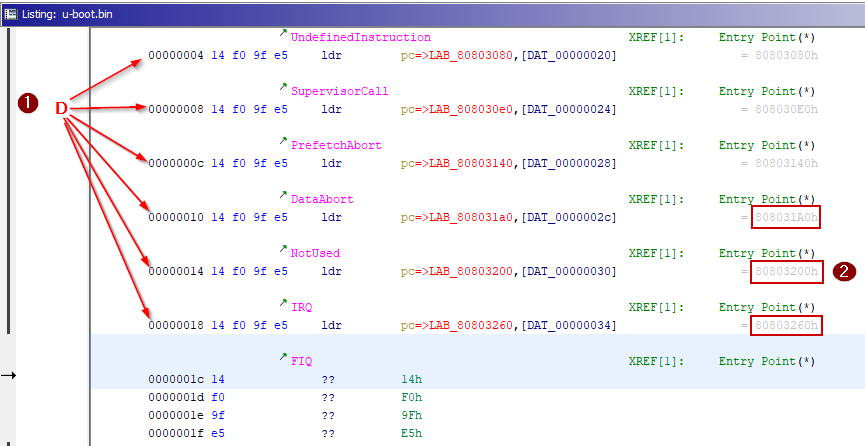
最后,我们可以重新定位Ghidra的内存块地址,并添加丢失的内存块(例如 RAM),这可以让Ghidra更好地分析二进制。
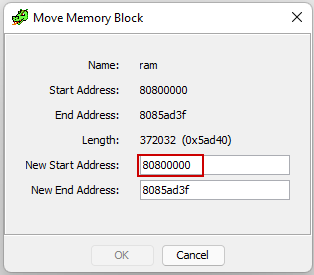
在适当地配置内存块之后,我们可以看到Ghidra正确地标识了所有的引用!
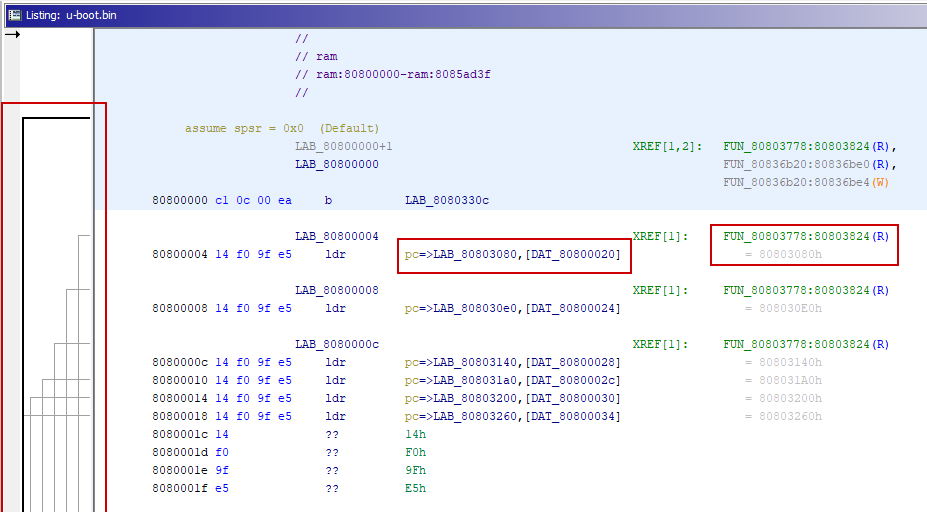
我们现在可以通过主动搜索ARM指令来触发Ghidra的自动分析。
注意:有时主动指令查找器会将某些数据块定义为代码,因此要注意。
利用开源的优势 因为我们有一个U-Boot的自定义实现,我们选择做两件事:
- 定义通用函数(它是一个静态的二进制文件,不依赖到任何libC)
- 导入U-Boot头文件并创建自定义DataTypes库
因此,我们开始阅读DAS-U-boot的一些源代码,并迅速识别出memcpy、memcp和printf等函数导出的位置,然后在待分析的二进制文件中搜索它们的代码模式。
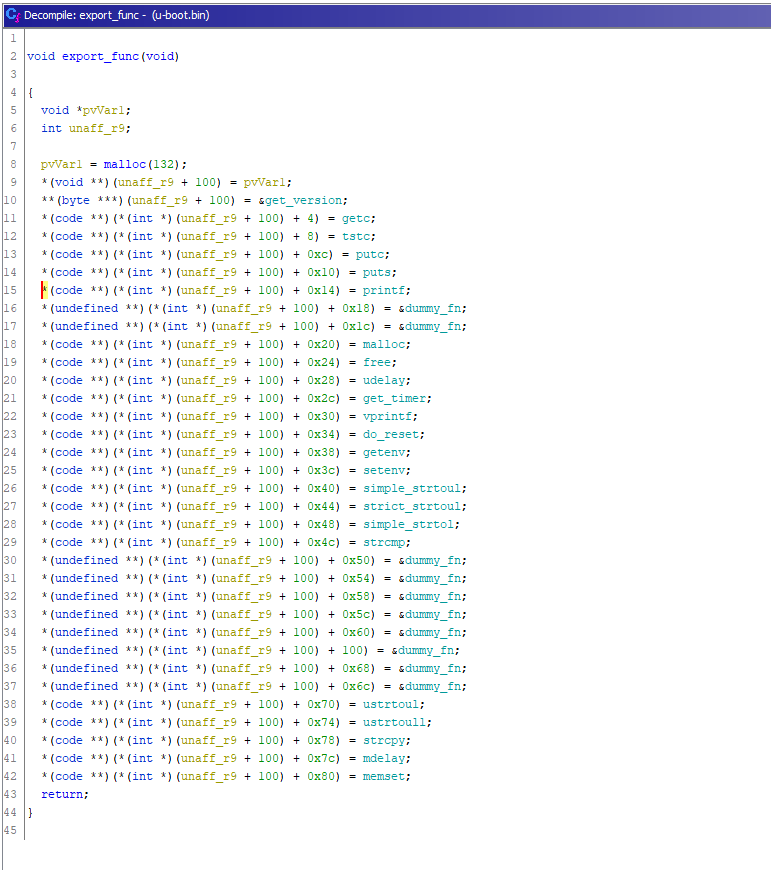
同时,我们也开始构建自定义的DataTypes库。Ghidra对导入头文件和自动解析其他导入有很好的支持。有时如果选择只导入几个头文件,则可能需要修改导入顺序。这个过程远不是一个自动任务能完成的,需要人工去修复头文件。
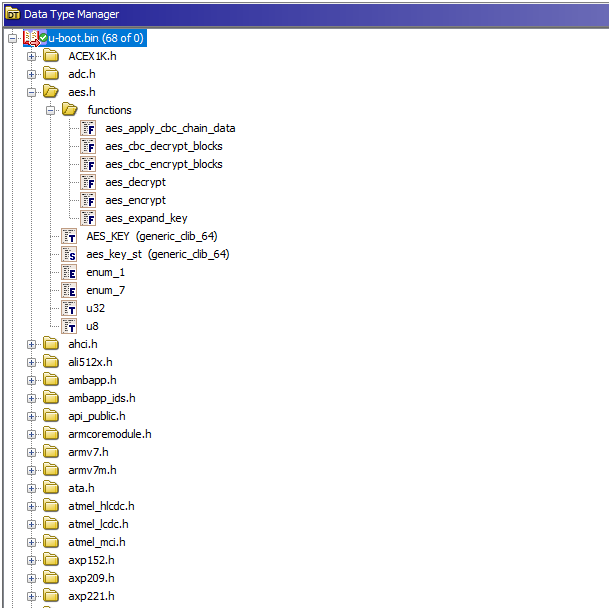
我们终于在Ghidra中有了一个易于浏览的项目,接下来可以跳到处理加密的地方分析了。
谁不爱逆向加密算法? 我们
现在我们确切地知道了引导过程的步骤
- 加载并执行自定义U-Boot bootloader
- U-Boot把加密的Linux内核加载到内存
- U-Boot对一些硬编码的数据执行密钥派生(记住,该设备不使用ARM Trust Zone)
- 内核在内存中被解密
- bootloader执行内核
- 内核可能会解密rootfs,因为bootloader没有实现这样的功能
我们仍然不知道解密机制是如何实现的,因为它是自定义的,没有出现在U-Boot源代码中,所以我们开始在代码中搜索通用的密码常量,以识别使用的密码算法。
基本上,大多数密码算法都有一些用于执行各种类型操作的常量。例如初始化向量、种子、基点、S盒等。
当用编程语言实现密码算法时,这些常量将作为数据嵌入到程序中,并(在我们的例子中)编译成二进制文件。因此即使二进制被strip过,也可以搜索这些常数出现的位置、跟踪使用它们的函数、识别使用了哪些加密算法等。
接下来,我们在bootloader二进制文件上使用ghidra-findcrypt看看
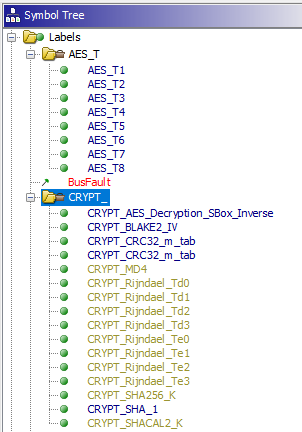
注意:ghidra-findcrypt检测到BLAKE2 IV,但这是假阳性误报,因为BLAKE2b IV与SHA-512 IV相同,BLAKE2s IV与SHA-256 IV相同。

例如,在上图中,我们可以看到在一些变量重命名和类型定义之后的AES解密函数。现在的代码可读性比以前强多了,我们可以将其与标准AES解密函数进行对比,看看它们是否相同。事实上确实如此!
现在我们知道AES用于解密数据,而SHA1用于密钥派生。我们最初的想法是获取加密密钥和函数参数,并编写一个python脚本来解密内核。

不幸的是,它使用了一种奇怪的操作模式。
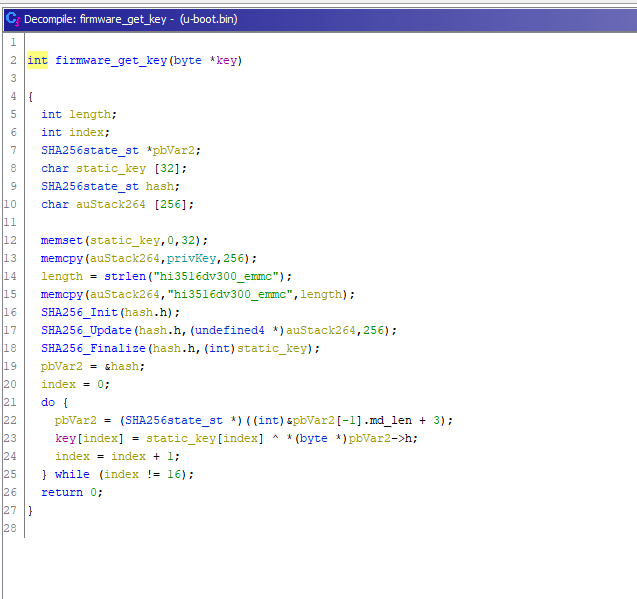
注意:上图仅是解密过程和密钥派生中涉及的多个函数中的一个。
此时,我们有两个选择:
- 忽略令人头痛的问题,继续反转加密算法,并开始重新实现它
- 创新
正如你可能猜到的,我们讨厌头痛,我们喜欢创造力!在下一篇博文中,我们将解释如何使用逆向工程过程中收集到的信息来模拟U-Boot并解密内核!
请继续关注!
作者zi0black: 特别感谢《A Guide to Kernel Exploitation》的作者Enrico twiz Perla,感谢他对这篇博文的同行评审,感谢他一直以来的帮助和善意。
参考资料
- http://classweb.ece.umd.edu/enee447.S2016/ARM-Documentation/ARM-Interrupts-3.pdf
- https://www.design-reuse.com/articles/38128/method-for-booting-arm-based-multi-core-socs.html
- https://stackoverflow.com/questions/6139952/what-is-the-booting-process-for-arm
- https://iitd-plos.github.io/col718/ref/arm-instructionset.pdf
- https://interrupt.memfault.com/blog/how-to-write-linker-scripts-for-firmware
- https://www.vinnie.work/docs/embeddedsystemsanalysis/firmware/baremetalbinary/
- https://www.coranac.com/tonc/text/asm.htm
- https://azeria-labs.com/writing-arm-assembly-part-1/